What is RAG (Retrieval-Augmented Generation) and Why It’s Crucial in 2025
Table of Contents
Subscribe To Our Newsletter

2025 is the year businesses drew the line and stop accepting the AI guesswork. With Generative AI going mainstream and flooding into boardrooms and products, a new demand is echoing across industries—give us accuracy, give us context, give us AI we can trust. Just being smart isn’t enough anymore. Enterprises demand advanced systems that know what they’re saying and where the facts come from.
Foundational models like GPT-4, Claude, and Gemini are undeniably powerful, but they too have a blind spot. They’re inherently static, and trained on frozen snapshots of the past, not the fast-moving present. For enterprises, that’s a problem. This limits their utility in real-world enterprise scenarios. As in, business decisions rely on up-to-date, trustworthy information, not on outdated facts or generic predictions.
Here comes RAG (Retrieval-Augmented Generation). Originally introduced by Meta AI in 2020, RAG AI has evolved into a foundational architecture in 2025. By integrating live retrieval with generative capabilities, RAG retrieval augmented generation brings the best of both worlds: the reasoning abilities of LLMs and the freshness of external knowledge.
As Satya Nadella aptly puts it, “AI is not just about being generative; it’s about being grounded.” That’s exactly what RAG achieves.
Understanding RAG
RAG (Retrieval-Augmented Generation) is a hybrid AI architecture that enhances large language models by connecting them with external, dynamic knowledge bases. Think of it as combining a search engine with a chatbot that remembers everything.
Instead of relying solely on pre-trained data, RAG models fetch relevant documents in real time and generate responses based on both the user’s query and the fetched data. So, if you’re wondering, “what is RAG retrieval augmented generation?” — it’s the future of trustworthy AI.
This system is increasingly being built into enterprise-grade solutions to handle everything from customer support automation to regulatory audit preparation. By blending static memory with retrieval pipelines, RAG essentially evolves LLMs from isolated engines to deeply integrated business intelligence agents.
How Does RAG Work?
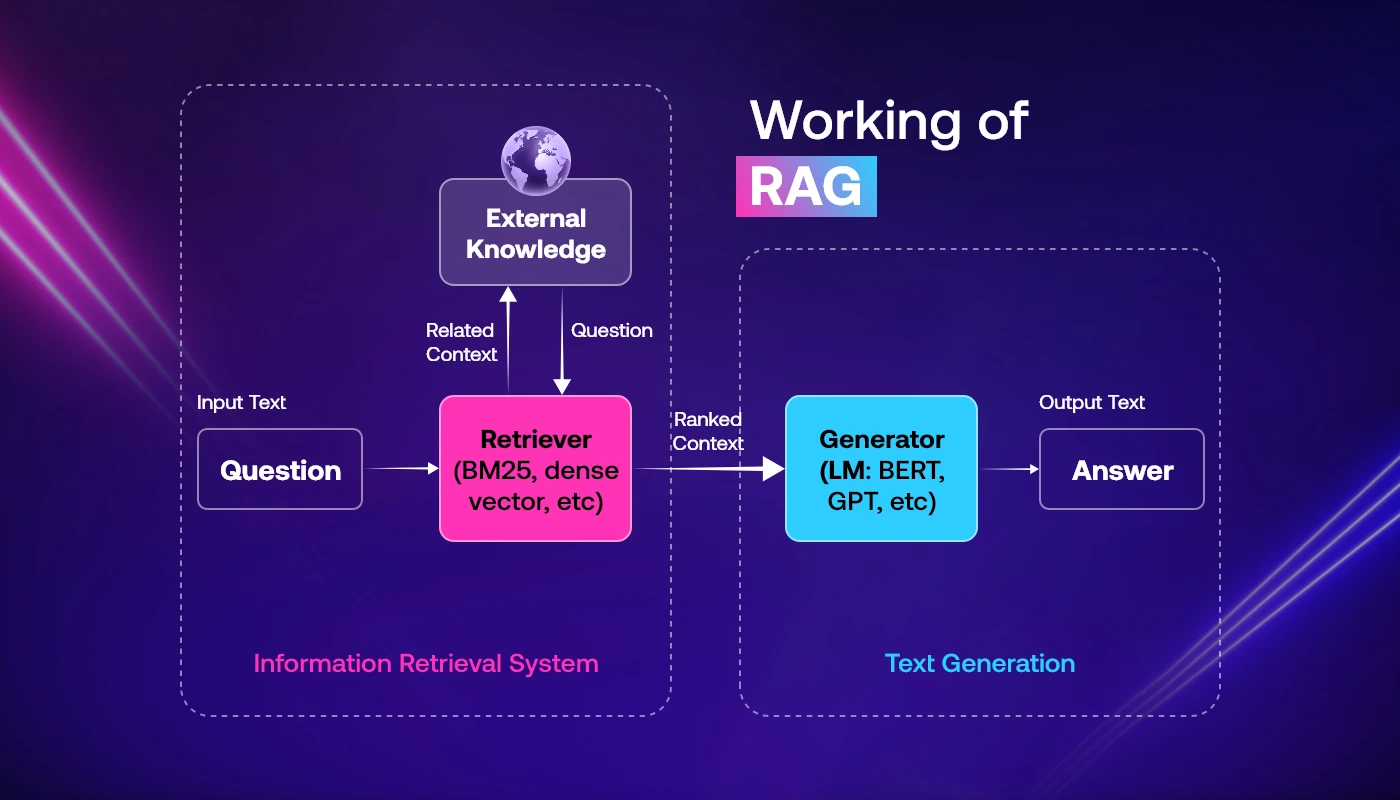
Here’s how retrieval augmented generation (RAG) operates under the hood:
-
Indexing
The system turns documents into numeric vectors that represent meaning, then stores them in a special format that makes it fast and easy to search later.
-
Retrieval
When a user asks a question, it is also turned into a vector and compared with stored vectors to find the most relevant documents quickly.
-
Augmentation
The system adds the best-matching documents to the user’s question, giving the AI more helpful information to better understand the request.
-
Generation
Using the question and added documents, the AI writes a response that is accurate, detailed, and based on real information from the database.
This process ensures factual, context-aware outputs. If you’re asking, “how does retrieval augmented generation work?” And, that’s the simplest yet most powerful explanation. Its benefit lies in its adaptability across modalities. The architecture can be extended beyond text and image-based vector stores can feed visual search assistants in e-commerce or radiology.
Cut Hallucinations by 80% and Boost Response Accuracy by 65%?
With RAG (Retrieval-Augmented Generation), enterprises are seeing a 3X improvement in factual consistency and compliance. No more outdated data. No more guessing games. Just trustworthy, context-rich AI responses in real time.
Join the 70% of AI-first companies adopting RAG to power next-gen apps in 2025.
Why RAG Is a Game-Changer for Enterprise AI
By 2025, RAG AI is no longer optional for serious AI deployments. Here’s why businesses are rapidly adopting RAG retrieval augmented generation:
-
Reduces False Information
RAG uses real documents to create answers, which helps the AI stay accurate. This cuts down on made-up responses and gives users more reliable, fact-based outputs they can trust.
-
Provides Real-Time Information
RAG retrieves fresh information from live sources and does not rely on stale training data. This way, users always get the most recent information, perfect for fast-paced topics like finance or news.
-
Adds Source References
RAG provides its source with every answer. This allows you to verify where the information came from, which is crucial in industries that need proof, such as health care or law.
-
Supports Smart AI Reasoning
RAG helps AI agents search, understand, and act based on the situation. It boosts their ability to reason and respond meaningfully, instead of giving random or unrelated answers.
-
Ensures Compliance and Traceability
For regulated sectors like legal or medical, RAG meets the need for traceable, verifiable responses. It keeps a clear trail of sources, helping businesses stay compliant with industry rules.
Gartner predicts that by 2026, over 40% of enterprise AI applications will integrate retrieval-based architectures to ensure regulatory compliance.
In fact, insurance firms and financial services providers are building RAG-driven tools to meet audit and documentation demands, replacing laborious manual processes. With increasing pressure from compliance bodies, traceability is not a bonus, it’s the benchmark.
Key Use Cases of RAG in 2025
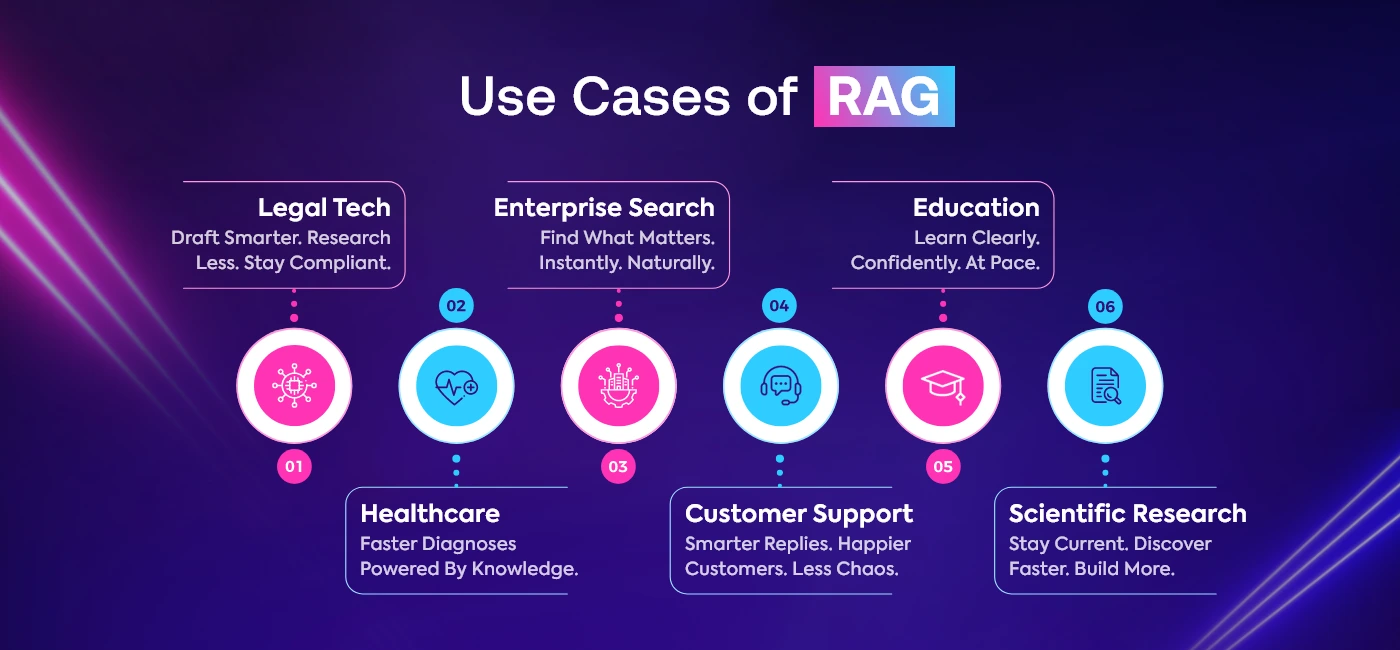
In 2025, RAG application spans nearly every industry:
-
Legal Tech
With AI tools that search for the latest case laws and regulations, contract drafting becomes faster and more accurate. Legal teams can cut down on manual work and errors, keep every document up-to-date with the latest legal standards without spending hours doing research.
-
Healthcare
Doctors now have access to real-time findings from thousands of clinical studies. Modern AI tools assist inform diagnostic decisions especially for complicated cases. As in, these tools have ability to identify relevant, evidence bases information that would take hours to retrieve manually.
-
Internal Enterprise Search
Employees can type questions like “Q3 sales deck” or “updated leave policy” and receive the exact document in seconds. Natural language understanding helps cut down wasted time spent digging through drives, folders, or old email threads.
-
Customer Support
Now, support teams are using AI to respond more quickly and accurately. Customer support desk provides an answer that combines the same set of responses, but drawing them from a knowledge base, FAQs and previous tickets to quickly deliver solutions to customer queries. This help in freeing up agents to concentrate on more pressing or complicated problems.
-
Education
Students receive assistance aligned to their curriculum and pace of learning. Rather than some cryptic answer, smart tutoring systems give you clear, level-appropriate explanations that actually makes sense. All these things help you learn faster and with more confidence.
-
Scientific Research
With new research published daily, staying current is tough. AI tools now scan publications, highlight key insights, and provide clean citations. This helps researchers filter the noise, stay updated, and focus more on building new ideas.
If you’ve ever searched for a retrieval augmented generation example, these real-world use cases are proof.
RAG vs Traditional LLMs
When you ask “what does RAG stand for in AI?”, it stands for a smarter, safer approach. The table given below reflects how real enterprises are shifting procurement decisions. RAG-based solutions now have a procurement advantage in sectors like fintech and pharmaceuticals, where audit trails are critical.
| Feature | Traditional LLM | RAG Model |
| Knowledge Source | Static | Dynamic (retrieved) |
| Update Frequency | Low | High (real-time updates) |
| Hallucination Risk | High | Low |
| Transparency | None | High (citable sources) |
| Best for Regulated Fields | No | Yes |
How Enterprises Can Leverage RAG
Implementing RAG AI doesn’t mean reinventing the wheel. Here’s how businesses are doing it:
-
- Use Open-Source Frameworks: LangChain, LlamaIndex, Haystack.
- Choose Vector Databases: Pinecone, Weaviate, Qdrant, FAISS.
- Import Internal Content: PDFs, CRM notes, Notion pages, ERP logs.
- Adopt Hybrid Search: Combine semantic + keyword (BM25) search.
- Deploy RAG in Workflows: CRM assistants, legal bots, healthcare dashboards.
- Power AI Agents: Pair with CrewAI or AutoGen to build autonomous agents.
Looking to Deploy RAG in Your Enterprise Workflows?
Over 68% of enterprises are embedding RAG into mission-critical systems, from legal compliance bots to AI-powered CRMs.
Don’t fall behind. Launch your production-ready RAG solution with Codiant in week.
Real-World Examples of RAG in Action
Here’s a quick look at how different industries are putting RAG (Retrieval-Augmented Generation) to work.
| Companies Using RAG | RAG Applications | Advantages |
| Google SGE | Uses RAG to fetch live web results and cite trusted sources in real-time. | Delivers more accurate, transparent, and up-to-date search experiences. |
| NVIDIA | Developed an internal bot that answers employee questions using secure enterprise data. | Boosts productivity and ensures faster access to internal information. |
| Meta AI | Open-sourced multilingual RAG models tailored for specific domains and languages. | Enables global teams to build language-aware, domain-specific applications faster. |
| Cohere | Provides domain-specific RAG stacks for industries like legal, finance, and retail. | Reduces setup time and improves retrieval accuracy in regulated industries. |
| Healthcare Assistants | Suggests treatments by retrieving verified medical studies and clinical publications. | Improves diagnostic confidence and shortens time to treatment recommendations. |
Future of RAG and LLMs in 2025 and Beyond
The evolution of Retrieval-Augmented Generation is far from over. As business needs grow more complex, RAG is transforming into something smarter, faster, and deeply integrated across languages, formats, and workflows. Here’s what’s coming next.
-
Context-Aware Dynamic Retrieval
RAG systems will adapt retrieval based on user behavior, task history, and session context—resulting in sharper, more personalized responses that align with real-time user intent and enterprise workflows.
-
Fusion of Retrieval and Parametric Memory
Future RAG models will blend external documents with internally trained knowledge, allowing them to deliver both precision and reasoning without sacrificing either depth or recency of information.
-
Multimodal Retrieval-Augmented Generation
RAG won’t stop at text. It will begin to process visual formats like PDFs, graphs, tables, screenshots, and source code—opening up entirely new possibilities for technical and visual reasoning.
-
Autonomous Agent-Based RAG
RAG will empower intelligent agents that don’t just retrieve but also take action—navigating tools, completing tasks, and making decisions across apps and workflows without human prompts.
-
Cross-Language Retrieval and Response
Users will be able to ask questions in one language and receive accurate, well-contextualized answers from sources in another—breaking language barriers for global teams and businesses.
-
Feedback-Driven Learning with RLHF
As users interact, RAG models will learn continuously. Human feedback will help them refine results over time, improving accuracy, tone, and relevance through reinforcement learning.
As Reid Hoffman noted, “The future belongs to those who can contextualize AI with live knowledge.” RAG is that bridge.
Challenges in Retrieval-Augmented Generation
Even with its potential, RAG isn’t free from pitfalls. From irrelevant document pulls to rising costs and privacy risks, understanding these common roadblocks helps you design a more stable and accurate generation pipeline from the ground up.

-
Poor Retrieval Reduces Output Quality
If your system retrieves irrelevant or low-quality documents, the generated answers will also lack accuracy, clarity, or usefulness—this is a direct dependency in any RAG pipeline.
-
Multi-Step Process Increases Latency and Costs
Retrieval and generation is both slow and resource intensive. This negatively impacts performance and makes scaling costlier, particularly in real-time or high-volume use cases.
-
Measuring Factual Accuracy Is Still Complex
It’s difficult to benchmark how factually correct RAG-generated content is, especially since knowledge bases and facts keep evolving across different domains and languages.
-
Too Many Documents Confuse the Model
Overloading the model with too much retrieved content can lead to fragmented answers, hallucinations, or contradictory outputs. Precision matters more than quantity in most retrieval scenarios.
-
Sensitive Data in Vector Stores Needs Protection
If you’re using internal or proprietary data for extraction, you need to make sure everything you’re storing is encrypted and access restricted. This way, the stored content remains protected and no data leaks occur.
Best Practices for Building Effective RAG Systems
RAG isn’t as simple as hooking up a retriever to a generator. With the best practices mentioned, you have a system that is reliable, efficient, and domain-informed. This will allow you to serve more high-quality outputs users can rely on.
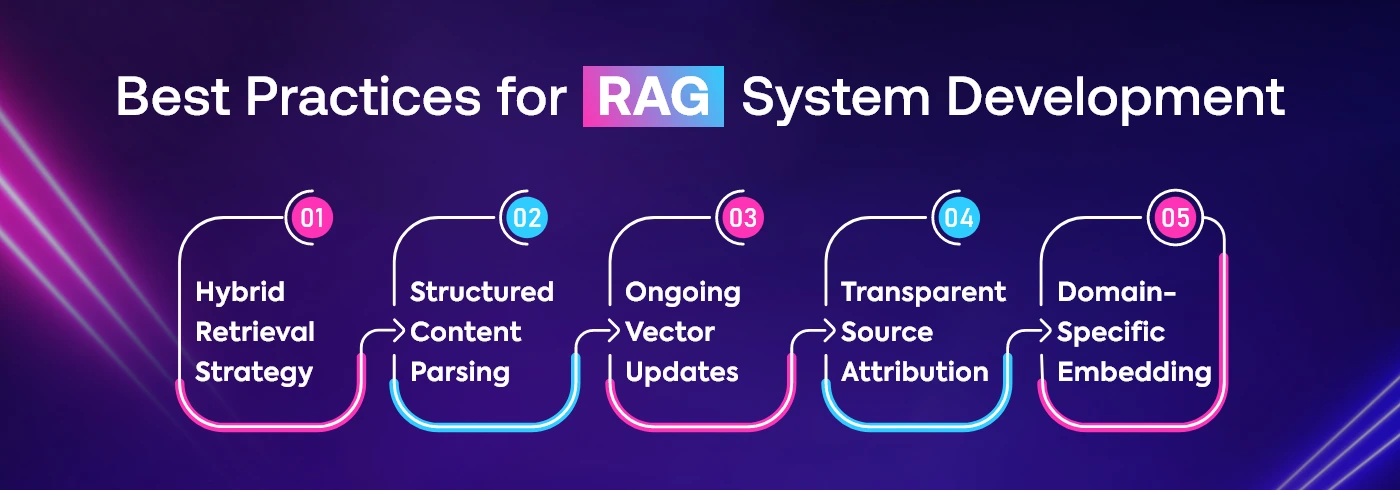
-
Use Both Keyword and Semantic Search Together
Combining BM25 keyword-based search with semantic vector search ensures better retrieval relevance and increases the chances of finding the most useful source documents.
-
Add Metadata and Chunk Content Smartly
Segment documents into meaningful chunks and attach metadata like document type or date. This allows the retriever to narrow down results with greater precision.
-
Refresh Your Vector Store Regularly
As your source content changes or grows, make sure the embeddings are periodically updated to reflect new information, ensuring the RAG model stays accurate over time.
-
Always Show Source References with Output
Include citations or links to the original content that informed the generation. This builds user trust and helps in verifying facts quickly.
-
Use Embedding Models Trained on Your Domain
Instead of generic language models, opt for domain-specific embeddings like LegalBERT or BioBERT. These understand terminology better and improve retrieval relevance in specialized fields.
Read also: How HVAC Companies in USA Use Chatbots and AI to Improve Customer Service?
Final Thoughts
AI in 2025 isn’t about novelty—it’s about trust. Businesses now prioritize accuracy over entertainment. And RAG (Retrieval-Augmented Generation) delivers.
By integrating real-time information, grounding responses, and reducing hallucinations, RAG retrieval augmented generation sets the foundation for safe, scalable, and transparent AI.
From Fortune 500s to agile startups, RAG is becoming the default. Because in the new AI economy, trust isn’t a feature, it’s a requirement.
- Poor Retrieval Fails
- Latency Drains Performance
- Factuality Remains Elusive
- Context Overloads Models
- Secure Sensitive Data
- Hybrid Retrieval Strategy
- Structured Content Segmentation
- Ongoing Vector Updates
- Transparent Source Attribution
- Domain-Specific Embeddings
The Author

Frequently Asked Questions
RAG is an AI architecture that enhances language models by retrieving external documents in real time to generate contextually accurate and up-to-date answers.
RAG works by converting user queries into vector form, retrieving top-matching documents, merging them with the prompt, and generating grounded responses using a language model.
RAG stands for Retrieval-Augmented Generation. It blends document retrieval and AI generation to produce more reliable outputs.
A RAG application is any AI solution that uses live document retrieval to generate answers. For example – legal contract drafting, healthcare bots, or enterprise search tools.
RAG reduces hallucinations, increases transparency, ensures compliance, and enables AI agents to act on live data—all critical for enterprise use cases.
LangChain, LlamaIndex, Haystack for orchestration; Pinecone, Weaviate, and FAISS for vector storage; paired with open-source or proprietary LLMs.
Featured Blogs
Read our thoughts and insights on the latest tech and business trends

How Much Does It Cost to Develop an AI System in Dubai?
- October 8, 2025
- Artificial Intelligence
KeyTakeaways: AI adoption in Dubai is booming - driven by the UAE’s AI Strategy 2031 and Dubai’s smart city vision. Costs vary widely- Small projects start around AED 70,000, while enterprise-grade AI platforms can exceed... Read more

Sustainability and AI in Focus- Deep Dive into the GITEX Global 2025 Agenda
- October 3, 2025
- Artificial Intelligence Gitex
Every October Dubai becomes the global capital of technology when GITEX Global opens its doors. This year GITEX Global 2025 (October 13th to 17th at Dubai World Trade Centre) is set to be the biggest... Read more

How HVAC Companies in USA Use Chatbots and AI to Improve Customer Service?
- October 1, 2025
- Artificial Intelligence
Key Takeaways: AI is no longer optional for HVAC – in 2025, over 70% of U.S. contractors have tested AI, and about 40% use it regularly. Chatbots improve response times by handling service requests instantly,... Read more
